“ContainerLaunchException: Container startup failed” when running Testcontainers with Gradle
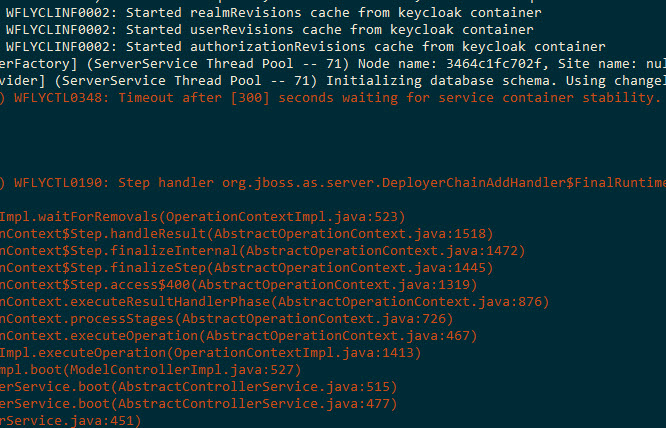
I had this nasty error when running integration tests with Testcontainers for my Java project with Gradle: SEVERE: Caught exception while closing extension context: org.junit.jupiter.engine.descriptor.ClassExtensionContext@669c884 org.testcontainers.containers.ContainerLaunchException: Container startup failed … Caused by: org.testcontainers.containers.ContainerFetchException: Can’t get Docker image: RemoteDockerImage(imageName=, imagePullPolicy=DefaultPullPolicy()) … Caused by: com.github.dockerjava.api.exception.DockerClientException: Error occurred while preparing Docker context folder. … Caused by: java.io.IOException: Der … Read more