
Why would anyone dismiss the good old Natural editor and switch over to NaturalONE? Let’s find out what features NaturalONE has to offer in the third episode of the Legacy Coder Podcast.
Podcast: Play in new window | Download
Why should you switch over to NaturalONE?
- Increased developer productivity
- Use Copy and Paste (duh!) for high quality Natural programming 😉
- Syntax Highlighting will help you understand the source code faster.
- Make use of intelligent search and replace features with regular expressions.
- Code Completion makes you type way less than before.
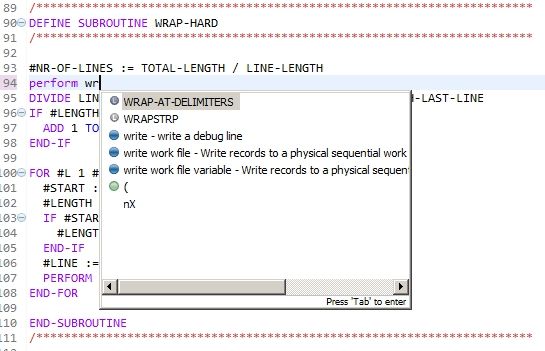
- Code Navigation (jump to a variable definition etc.) lets you explore the code base with a few keystrokes.
- You can use Code Folding for focussing on the really important stuff.
- Multiple compile errors are displayed instantly without uploading the source to the server.

- Repository based development
- Finally develop software like the cool kids do!
- Every code change is documented and can be rolled back with just a few commands. It can even be attached to an issue tracker like Jira or Redmine.
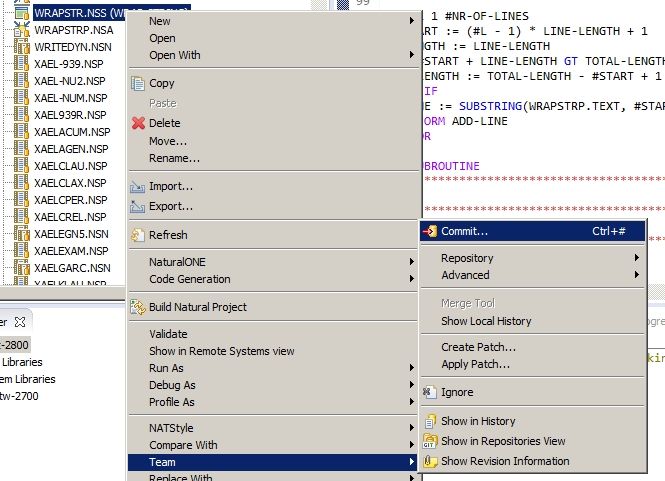
- You can try out new things in an isolated environment.
- You can automate your coding with code generators like Xtext.
- Modernize your development environment
- Share knowledge and open up towards other (maybe younger) developers (Java etc.).
- Be and stay attractive as a company to new employees.
- Automate your build process
- NaturalONE is Software AG’s platform of choice for the future.
- The old Natural editor will be shut down!
- Extendable with additional plugins
- Software AG’s innovations will only take place in NaturalONE (e.g. Code Coverage, Screen Testing).
- Attach your IDE to an issue tracker like Jira or Redmine with Mylyn.
- Use Snipmatch for even less typing.
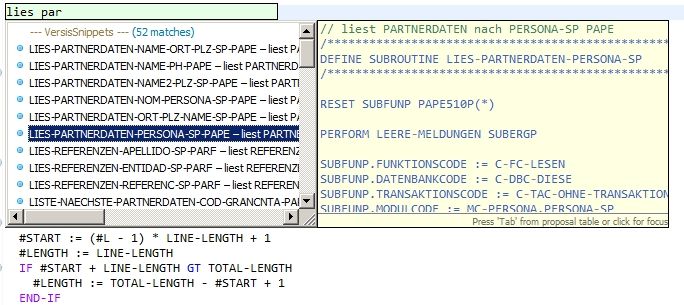
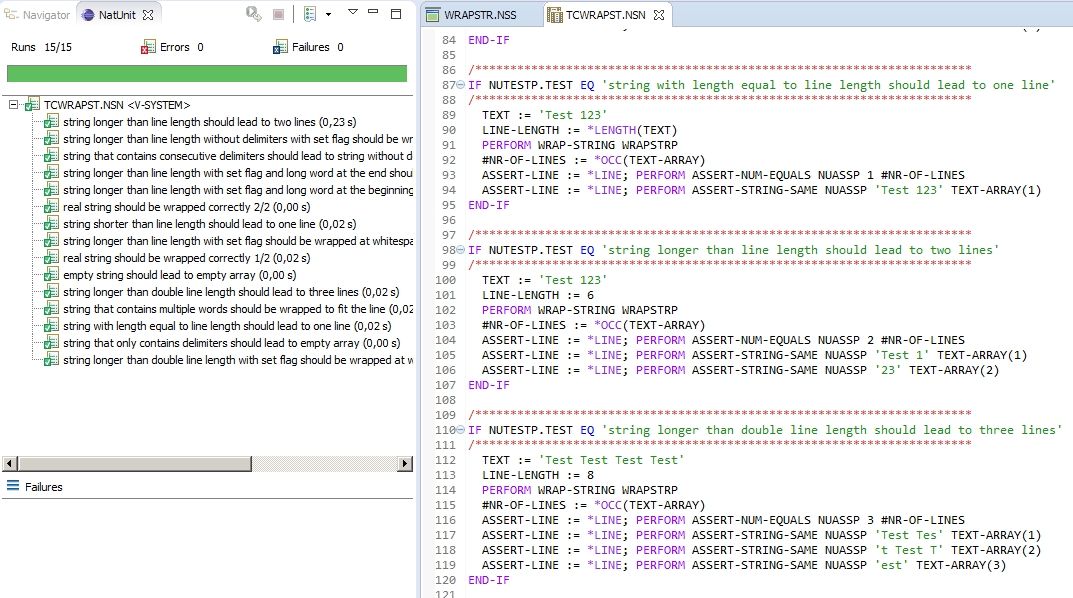
- Create your own extensions (e.g. NatUnit) for whatever requirement you have.
Recommended reading
- Automating Your Natural Build Process (with the help of NaturalONE)
- Recipe for Success: Mastering the Generational Change (you should provide state-of-the-art development tools to retain your staff)
- NaturalONE – The development environment for Natural: Agile development and DevOps attract new talent (a.k.a. Software AG shuts down the Natural editor)
- Learn how to do basic programming in Software AG’s NaturalOne.
- NaturalOne Debugging
Links
- Permalink for this Podcast episode
- RSS feed for the Legacy Coder Podcast
- Mylyn (Eclipse plugin for hooking your IDE up to an issue tracker)
- Snipmatch (Eclipse plugin for sharing code snippets among your teammates)
- Redmine (open source project management tool and issue tracker)
- Jira (commercial tool by Atlassian)
- Xtext (open source framework for writing Domain Specific Languages)
NaturalONE does not show compile error if we call a missing Suproutine using perform statement, why?
How to see Natural documentation or Comments on mouse hover on Subroutine in NaturalONE?
Is it possible to show natural documentation for reserved keywords, for example REPEAT.
I want something similar to Eclipse, when I just mouse hover on String then I can read Java API documentation about it. Is there hot key for that?
Hi Amjad, I’m not sure if this is possible. NatDoc can be generated as HTML documentation for your Natural modules, but I don’t think that NaturalONE will pick it up and display it inline in your editor.
As far as I know, NaturalONE can’t show you the Natural documentation for statements when hovering over them with your mouse. I think you’ll need to press F1 and take a look at the Natural help.
But your suggestions would be really nice features to have in NaturalONE! Why don’t you open up a Brainstorm issue for them?